17 7 / 2017
Getting amazon SNS ans SQS feelers with some benchmarks
We are exploring Amazon SNS and SQS services to build our notifications system at Pratilipi. To get started and have some initial idea about whether it works the way it has been promised, I decided to do some basic benchmarking. Please note that I did this on my local machine to know whether the technologies fit our usecase, or we can reject them outrightly. I am sharing these in the hope that someone else in a similar situation might find this helpful. These are not production benchmarks, and the sole purpose is to get some firsthand feelers.
Below are a couple of Node.js apps built using sails that I created to carry out these benchmarks:
- https://github.com/amitsaxena/sns_experiment (used to send a notification to SNS)
- https://github.com/amitsaxena/sqs_experiment (used to send and receive jobs to and from SQS)
I used the good old apache bench to generate concurrency and load. The requests were being served by a single node server instance on my local machine with an average internet connection. Below are the test results:
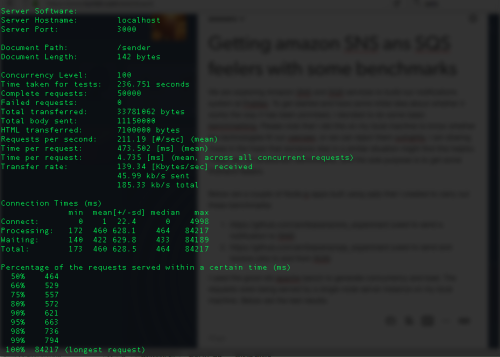
50K requests at 100 concurrency sending messages to SNS:
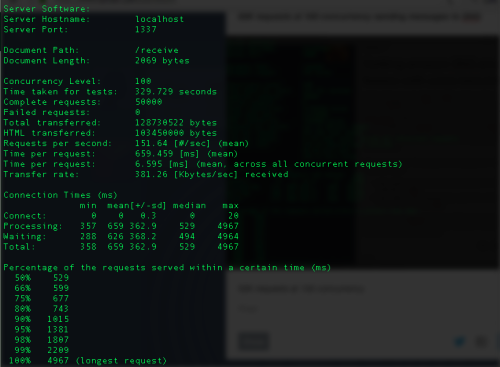
50K requests at 100 concurrency receiving messages from SQS:
To also account for network latency, I hit one of our ECS container instance in the same AWS region to get an average round trip time (time spent by our request/response in transferring data over network) for our requests.
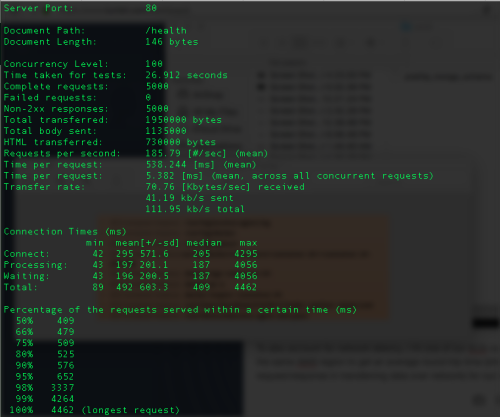
5K requests with 100 concurrency doing a health check
Below are my observations:
- The average time per request for sending messages to SNS is 474ms
- The average round trip time for our requests (health check) in the same AWS region is 538ms
- Looking at the above, feels like SNS is going to give us < 10 millisecond latency when we are going to trigger events and notifications from our app servers in the same AWS region as the SNS topics
- The average time taken to retrieve a message from SQS and delete it as well is 660ms
- Taking into account the network latency, it looks like it will take around 150ms to retrieve and delete a job from SQS (from our app servers)
- There were 0 failures when sending 50K messages
- There were 0 failures when retrieving 50K messages
Based on the above data it feels like that both SNS and SQS are good pieces of technology for the problems we are trying to solve here. We are fine with a few seconds of lag in our notifications system and are planning to go ahead with these.
If you have any questions or thoughts to share, please feel free to shoot a comment. How has your experience with SNS and SQS been?
11 11 / 2014
This is what is required when you sit to debug/enhance a crawler that you released into the wild-wild world of internet, with all kind oh HTML criminals roaming around. You often wonder whether they made mistakes, or if those were deliberate attempts to deface the internet. You hope that these people were in jail instead of producing code =P
Then the realization dawns upon you that the world of web is infinite, and you are but a minuscule drop in the ocean of world wide web. You make peace with yourself, and indulge in a lot of philosophy. Then you write code, which is all that really matters. Inner Peace!
23 10 / 2013
How to lose $172,222 a second for 45 minutes
That’s why ;)
This is probably the most painful bug report I’ve ever read, describing in glorious technicolor the steps leading to Knight Capital’s $465m trading loss due to a software bug that struck late last year, effectively bankrupting the company.
The tale has all the hallmarks of technical debt in a huge, unmaintained, bitrotten codebase (the bug itself due to code that hadn’t been used for 8 years), and a really poor, undisciplined devops story.
Highlights:
To enable its customers’ participation in the Retail Liquidity Program (“RLP”) at the New York Stock Exchange,5 which was scheduled to commence on August 1, 2012, Knight made a number of changes to its systems and software code related to its order handling processes. These changes included developing and deploying new software code in SMARS. SMARS is an automated, high speed, algorithmic router that sends orders into the market for execution. A core function of SMARS is to receive orders passed from other components of Knight’s trading platform (“parent” orders) and then, as needed based on the available liquidity, send one or more representative (or “child”) orders to external venues for execution.
13. Upon deployment, the new RLP code in SMARS was intended to replace unused code in the relevant portion of the order router. This unused code previously had been used for functionality called “Power Peg,” which Knight had discontinued using many years earlier. Despite the lack of use, the Power Peg functionality remained present and callable at the time of the RLP deployment. The new RLP code also repurposed a flag that was formerly used to activate the Power Peg code. Knight intended to delete the Power Peg code so that when this flag was set to “yes,” the new RLP functionality—rather than Power Peg—would be engaged.
14. When Knight used the Power Peg code previously, as child orders were executed, a cumulative quantity function counted the number of shares of the parent order that had been executed. This feature instructed the code to stop routing child orders after the parent order had been filled completely. In 2003, Knight ceased using the Power Peg functionality. In 2005, Knight moved the tracking of cumulative shares function in the Power Peg code to an earlier point in the SMARS code sequence. Knight did not retest the Power Peg code after moving the cumulative quantity function to determine whether Power Peg would still function correctly if called.
15. Beginning on July 27, 2012, Knight deployed the new RLP code in SMARS in stages by placing it on a limited number of servers in SMARS on successive days. During the deployment of the new code, however, one of Knight’s technicians did not copy the new code to one of the eight SMARS computer servers. Knight did not have a second technician review this deployment and no one at Knight realized that the Power Peg code had not been removed from the eighth server, nor the new RLP code added. Knight had no written procedures that required such a review.
16. On August 1, Knight received orders from broker-dealers whose customers were eligible to participate in the RLP. The seven servers that received the new code processed these orders correctly. However, orders sent with the repurposed flag to the eighth server triggered the defective Power Peg code still present on that server. As a result, this server began sending child orders to certain trading centers for execution.
19. On August 1, Knight also received orders eligible for the RLP but that were designated for pre-market trading.6 SMARS processed these orders and, beginning at approximately 8:01 a.m. ET, an internal system at Knight generated automated e-mail messages (called “BNET rejects”) that referenced SMARS and identified an error described as “Power Peg disabled.” Knight’s system sent 97 of these e-mail messages to a group of Knight personnel before the 9:30 a.m. market open. Knight did not design these types of messages to be system alerts, and Knight personnel generally did not review them when they were received
It gets better:
27. On August 1, Knight did not have supervisory procedures concerning incident response. More specifically, Knight did not have supervisory procedures to guide its relevant personnel when significant issues developed. On August 1, Knight relied primarily on its technology team to attempt to identify and address the SMARS problem in a live trading environment. Knight’s system continued to send millions of child orders while its personnel attempted to identify the source of the problem. In one of its attempts to address the problem, Knight uninstalled the new RLP code from the seven servers where it had been deployed correctly. This action worsened the problem, causing additional incoming parent orders to activate the Power Peg code that was present on those servers, similar to what had already occurred on the eighth server.
The remainder of the document is definitely worth a read, but importantly recommends new human processes to avoid a similar tragedy. None of the ops failures leading to the bug were related to humans, but rather, due to most likely horrible deployment scripts and woeful production monitoring. What kind of cowboy shop doesn’t even have monitoring to ensure a cluster is running a consistent software release!? Not to mention deployment scripts that check return codes..
We can also only hope that references to “written test procedures” for the unused code refer to systematic tests, as opposed to a 10 year old wiki page.
The best part is the fine: $12m, despite the resulting audit also revealing that the system was systematically sending naked shorts.
[Edit: seems this was posted a little too quickly: the final loss was $460m and the code was dead for closer to 9 years, not 8]