20 6 / 2018
02 5 / 2018
Recently read a post about a**hole designs by @flaviolamenza and just came across one by Apple!
https://uxdesign.cc/stop-calling-these-dark-design-patterns-or-dark-ux-these-are-simply-asshole-designs-bb02df378ba
30 11 / 2017
API authentication: How is JWT authentication (with refresh tokens) superior to having an API token per user?
I am trying to add authentication to my API. Have been reading a lot about JWT and how popular it has been, but somehow I haven’t been able to get my head around a few things. I have some fundamental questions about JWT, why is it superior and the de facto standard for API authentication these days. Really grateful to anyone who can help me with these questions - please add your comments below!
Below are the possible approaches:
Using API token per user:
- There is an endpoint (https) where you can send email and password to generate an API token for the given user. The token scopes all subsequent API calls to the given user.
- The token obtained in (1) is used in all API calls for the given user and is stored locally on the client.
- If password changes (or in case I want to invalidate token on some other event) I reset the token and user needs to log in again and regenerate an API token. I can also associate an expiry with it if I need to.
Using JWT:
- There is an endpoint (https) where you can send email and password to generate a JWT token with user info in it and an associated expiry.
- The JWT obtained in (1) can be used for all subsequent API calls, but since I cannot log out user on expiry of JWT (bad UX) and I cannot directly invalidate a JWT in contingency, I’ll need to use refresh tokens as well.
- Now if the token is expired, generate a new JWT token using the refresh token. I see this as an extra API call which adds to latency and is an overhead. Now use this new token in subsequent calls.
- On password change reset the refresh token to force login.
Questions:
- How is JWT superior to the API token approach?
- Both hit the DB (JWT for refresh tokens).
- JWT has an additional overhead to maintain refresh tokens, and more importantly an extra call to get a new JWT using refresh token on each expiry. In fact some approaches suggest a token refresh call before each API request to extend expiry of JWT.
- Invalidating JWT is tricky, and hence the refresh tokens. Isn’t it doing the same thing (DB hit) in a much more complicated manner.
- The JWT could grow in size and we’ll need to send it with every request. So the concept of avoiding DB hit is sort of incorrect (catch-22) - we cannot have everything in the payload, so we will anyways need to query DB.
- Few people might say that JWT might not be suited for my use case, but I would like to know what use cases is it suited for. Also in particular which mechanism is better for authenticating APIs where there is a concept of user who needs to log in.
06 9 / 2017
If you are using sails with waterline and struggling with timezones, try this first
I am using node.js framework sails which internally uses the Waterline ORM and while saving a record to MySQL the auto-generated timestamps (createdAt and updatedAt) were being saved in local timezone instead of being saved in UTC. After wasting a few hours, this fixed it for me:
Hope this helps someone save a few hours!
02 9 / 2017
Migrations with Node.js
Given the minimalist node philosophy this doesn’t come with the package, and given my rails background it’s hard for me to imagine a world without migrations. In case you feel the same way, below is a quick start guide to get you up and running with migrations in a node app within two minutes:
17 7 / 2017
Getting amazon SNS ans SQS feelers with some benchmarks
We are exploring Amazon SNS and SQS services to build our notifications system at Pratilipi. To get started and have some initial idea about whether it works the way it has been promised, I decided to do some basic benchmarking. Please note that I did this on my local machine to know whether the technologies fit our usecase, or we can reject them outrightly. I am sharing these in the hope that someone else in a similar situation might find this helpful. These are not production benchmarks, and the sole purpose is to get some firsthand feelers.
Below are a couple of Node.js apps built using sails that I created to carry out these benchmarks:
- https://github.com/amitsaxena/sns_experiment (used to send a notification to SNS)
- https://github.com/amitsaxena/sqs_experiment (used to send and receive jobs to and from SQS)
I used the good old apache bench to generate concurrency and load. The requests were being served by a single node server instance on my local machine with an average internet connection. Below are the test results:
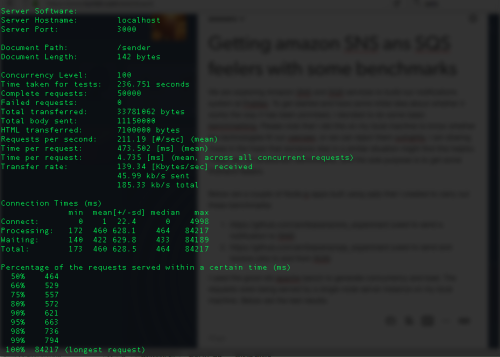
50K requests at 100 concurrency sending messages to SNS:
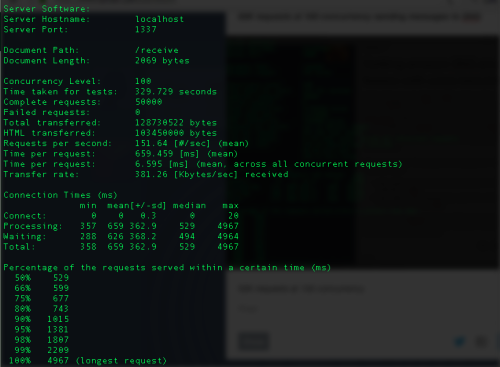
50K requests at 100 concurrency receiving messages from SQS:
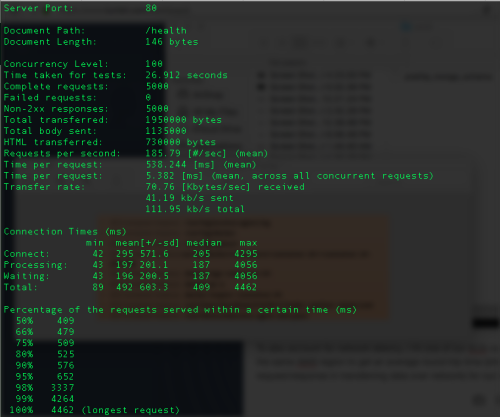
To also account for network latency, I hit one of our ECS container instance in the same AWS region to get an average round trip time (time spent by our request/response in transferring data over network) for our requests.
5K requests with 100 concurrency doing a health check
Below are my observations:
- The average time per request for sending messages to SNS is 474ms
- The average round trip time for our requests (health check) in the same AWS region is 538ms
- Looking at the above, feels like SNS is going to give us < 10 millisecond latency when we are going to trigger events and notifications from our app servers in the same AWS region as the SNS topics
- The average time taken to retrieve a message from SQS and delete it as well is 660ms
- Taking into account the network latency, it looks like it will take around 150ms to retrieve and delete a job from SQS (from our app servers)
- There were 0 failures when sending 50K messages
- There were 0 failures when retrieving 50K messages
Based on the above data it feels like that both SNS and SQS are good pieces of technology for the problems we are trying to solve here. We are fine with a few seconds of lag in our notifications system and are planning to go ahead with these.
If you have any questions or thoughts to share, please feel free to shoot a comment. How has your experience with SNS and SQS been?
04 7 / 2017
If you use Google cloud with Docker and are suddenly seeing an invalid_grant error, restart docker first!
May be this helps someone from hours of frustration and pointless debugging! A working piece of code suddenly started throwing ‘invalid_grant’ errors and after debugging for hours (IAM permissions, matching secret keys, extreme logging, and what not!) I finally realized that the time in docker container was behind my system time, and that was causing the errors. Looks like it is some docker bug which people are talking about here:
https://forums.docker.com/t/time-in-container-is-out-of-sync/16566
Restarting docker fixed it instantaneously. So if you ever find yourself in the above situation (or similar situation where a third party API call suddenly starts failing withing a docker container), restart docker before doing anything else.
21 6 / 2016
How to return a 404 response code for CloudFront requests (S3 origin) of a non-existent S3 object
If you are here, you already know that you get a 403 response code (unauthorized) for this scenario. I don’t want you to get drowned in the sea of confusing Amazon documentation. Below is how you can do it.
Open the AWS management console, and go to your specific bucket and click properties tab

Now under “Permissions” click “Edit bucket policy“

Your policy should look like something below. If you don’t have one, add a new one. Please note that this policy is used to access private content (via CloudFront) on S3, but it probably will work for public content as well.
10 6 / 2016
How to write an Active Admin custom filter (custom search)
This will work with pre 1.0.0 versions where active_admin used metasearch gem for filters. Below is how you can add a custom field as filter and use it to generate search results using a custom search function:
For me active_admin did break down when we added a polymorphic association to an existing model, and the filter on association stopped working. We suddenly started seeing “no implicit conversion of nil into String“ exceptions. I then had to figure out how to write a custom filter for active admin - and believe me it was like walking in the Sahara Desert =P , with little/no documentation around.
Do let me know in case this helped you and I saved you from getting lost in the great Sahara ;)

04 3 / 2016
How to build a product from scratch
Though people try and make it sound extraordinary, but it is more about getting started in the first place and making a lot of decisions along the way. I have done it a few times in the past, and I will try and dispel the myths. When you start working on version 1.0 of a product, you spend a lot of time thinking about the product and architecture. It’s good if you spend significant time thinking about what your product is going to do, and how you are going to do it (technically). Ask a lot of questions. Additionally, it will be great if you put some thought into how this thing is going to scale into the near future, and try and think about any immediate contingencies that you may face once your product is unleashed onto the real world (out of the one that exists in your thoughts). It never hurts to stay prepared, but at the same time I will advise against shooting in the dark. That’s dangerous, and that’s too managerial for me to care about. I don’t know if there will be any computers/mobile devices five years from now (or the world will have moved on to the next big thing), so when someone asks if this product is going to work 5 years from now, all I can spare is a smile. Remember, this is the first iteration of your product, and it will continue to evolve as the world evolves, or it is going to be dead soon!
So once you are done with the thinking bit, it’s all about decisions - what language, what framework, what databases, what server, what caching layer, which host. At a more micro level - what server configuration, what defaults and which gems. For the bigger decisions, I usually try and stick with technologies I already know, for the simple reason that I know them better. That doesn’t mean that new technologies don’t find a place, and it could vary from project to project. Usually they can come a bit later in the cycle, when I am more clear about whether or not this technology can solve the given problem. So while building v1.0, each day involves a lot of decisions on your part, and you need to stick with them for a while. There could be mistakes, and the earlier you rectify those, the better. Fail early, fail fast!
Other than the decisions, you will need to write a lot of code. Be possessive about your code, feel offended/guilty if anything breaks. If you touch someone else’s code, it’s your responsibility that nothing breaks. Stay away from the blame game. Behave responsibly. If something is ugly and needs to be rewritten, rewrite it. At the end of the day, do look at the code that you have written, and see if something can be done better. If it can be, do it. Love what you do. F#@k process, use your good judgement. You are here to build. You cannot fake excitement, and if you are not excited about what you are building, then neither can Agile help you, nor the Waterfall model.
Unleash the dragon, and once it’s out in the open, get ready for round two. Iterate, iterate, iterate until you create something that people love! And once people start loving what you have built, you have some other problems to solve - scale.
Remember there are no silver bullets or turn key solutions for scaling your product. If you know people who think this way, stay away from them. Those are dangerous people. It involves effort at your end, and sheer determination to solve that problem. Don’t look at it as just another bug in the system. Pay attention early enough, read the warning signs, and get to work. Those are interesting problems to solve, and you are lucky enough to have hit them. Most of the people you know have never heard of them, and never will. Thanks to the open source community, and treasures of information available over the internet, the world is a better place, and you are not alone. You will figure it out, and unknown people, who you will never meet, will help you get there. That’s humanity!
As programmers we have the rare gift of being able to create things, and bringing ideas to life. You are a problem solver. That’s too much power which you ought to use now. In the words of Steve Jobs:
“Designing a product is keeping five thousand things in your brain and fitting them all together in new and different ways to get what you want. And every day you discover something new that is a new problem or a new opportunity to fit these things together a little differently.
And it’s that process that is the magic.”

Life is short! Don’t waste it on things that don’t matter. Feel free to throw your random ideas at me, in case you are looking for feedback/brainstorming, or just trying to solve a difficult problem. I firmly believe in good karma, and humanity :)
If you build products some other way, things which have worked for you, do let me know in the comments section.